 Don't Miss Out:
Don't Miss Out: 
Robots.txt, with the cooperation of webmasters, acts as a guide for web robots. Using robots.txt without the right knowledge can be disastrous for your website.
In fact, if you create it by mistake in an important section of your site, the search engine robots would not crawl those web pages, and they will remain absent in the search results. Therefore, it is essential to know the value, the aim, and the right usage of a robots.txt file in SEO.
What’s Robots.txt?
In simple words, robots.txt file is used to restrict search engine crawlers from indexing selected areas of the website.
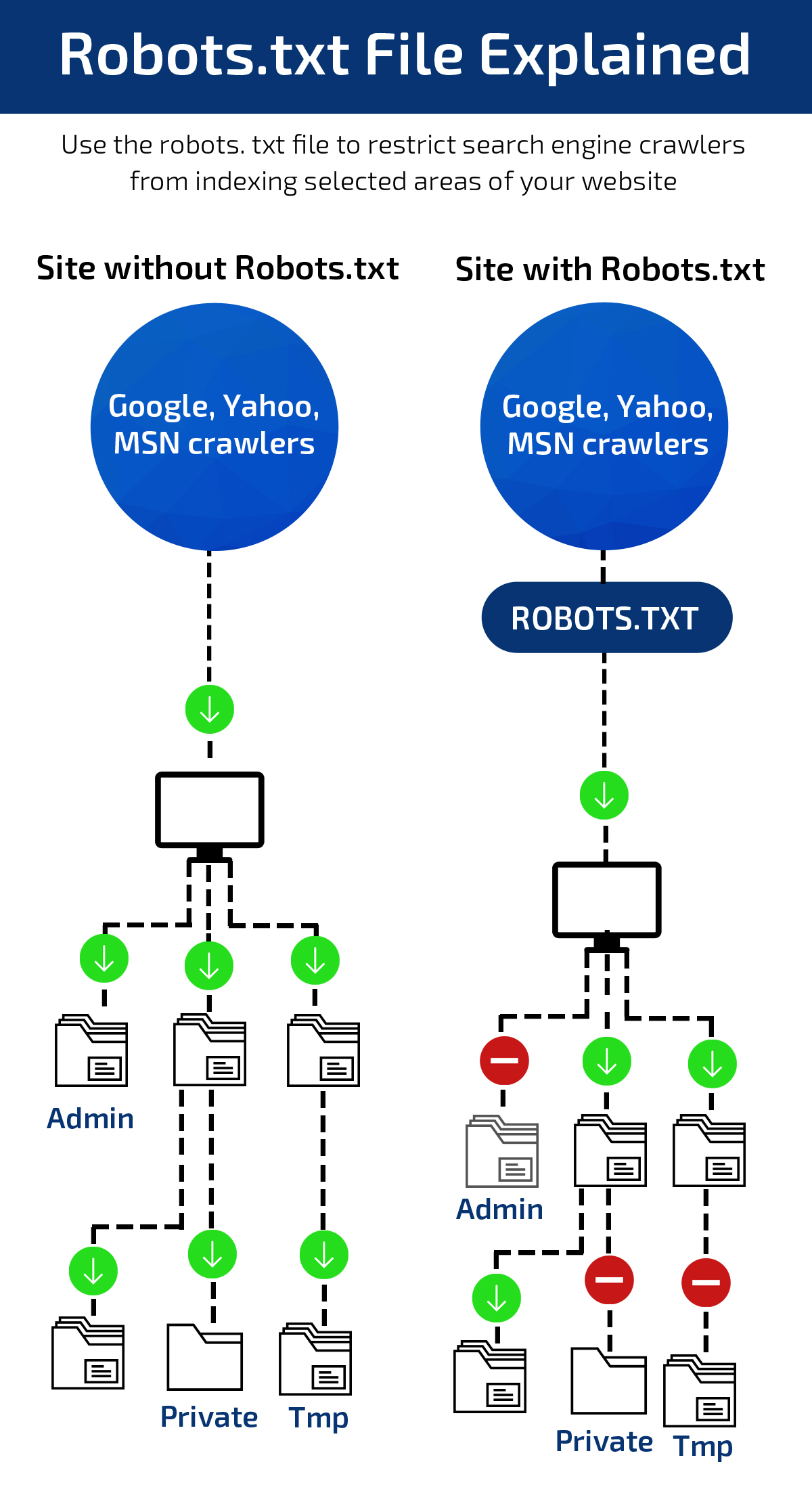
The Working Process
The robots.txt file guides the search engine robots for the web pages that a website owner does not want to be crawled. For instance, if a trader does not wish specific videos on his website to be listed by Google or other search engines, then they can be blocked easily with the use of a robots.txt file.
You can go to your website and check if you have a robots.txt file by adding /robots.txt immediately after your domain name in the address bar at the top:

The URL you enter should look like this: http://www.mywebsite.com/robots.txt (with your domain name instead!)
When you create this file for your website, the search engine robots will look at the robots.txt to crawl and index specific pages of your site.
How to create a robots.txt file
If your website does not have a robots.txt file, get one created as quickly as possible. If you want to do it yourself, follow the steps mentioned below.
- Create and save a new text file as “robots.txt”. Use the Notepad application on your Windows PCs or Text Edit on Mac before saving it as a text-delimited file.
- The text file created should be uploaded to the root directory of your website. The root directory is the root level folder called “htdocs” or “www” which makes it appear directly after your domain name.
- If you use sub domains, you will need to create a robots.txt file for each subdomain.
- txt is case sensitive. Make sure that the file is named “robots.txt” and not Robots.txt, robots.TXT, or any other spelling.
- The /robots.txt file is publicly available. Just add /robots.txt to the end of any root domain to see that website’s directives, that is, if that site has a robots.txt file! This means that anyone can see what pages you want or do not want to be crawled, meaning do not use it to hide private user information.
- It is best to indicate the location of any sitemaps associated with this domain at the bottom of the robots.txt file.
Technical robots.txt syntax
Robots.txt syntax is merely the “language” of robots.txt files. The standard terms you will most likely come across in a robots file are:
- User-agent: The specific web crawler to which you are giving crawl instructions (usually a search engine). A list of most user agents can be found here.
- Disallow: The command used to tell a user-agent not to crawl a URL. Only one “Disallow:” line is allowed for each URL.
- Allow (Only applicable for Googlebot): The command to tell Googlebot it can access a page or subfolder even though its parent page or subfolder may be disallowed.
- Sitemap: Used to call out the location of any XML sitemap(s) associated with this URL.
What should be in the robots.txt file?
It is difficult for many to agree about what should and should not be in robots.txt files. You need to understand that robots.txt is designed to act as a guide for web robots and not all robots will follow your instructions.
Here are some examples that will give you a clear understanding of using robots.txt file:
Allow everything and submit the sitemap
To allow a search engine to fully crawl a site and index all the webpage data, allowing everything and submitting the sitemap would serve the desired purpose. It will also help search engines locate XML sitemaps to discover new pages:
User-agent: *
Allow: /
#Sitemap Reference
Sitemap:http://www.mywebsite.com/sitemap.xml
Allow everything except from one sub-directory
At times, you do not want search engines to show something from your website on the search results, such as the checkout area, image files, an irrelevant part of a forum, or an adult section of a website. Any URL including the path disallowed will be excluded by the search engines:
User-agent: *
Allow: /
# Disallowed Sub-Directories
Disallow: /checkout/
Disallow: /website-images/
Disallow: /forum/off-topic/
Disallow: /adult-chat/
Allow everything apart from specific files
There could be instances when you want to show media files or documents on your website but do not want them to have visibility in image search results or document searches. For example:
User-agent: *
Allow: /
# Disallowed File Types
Disallow: /*.gif$
Disallow: /*.pdf$
Disallow: /*.PDF$
Disallow: /*.php$
Allow everything except certain webpages
There might be webpages on your site that appear unsuitable in search engine results. By using the robots.txt file, you can block individual pages, such as a terms and conditions page, a page with sensitive information, and more.
User-agent: *
Allow: /
# Disallowed Web Pages
Disallow: /terms.html
Disallow: /blog/how-to-blow-up-the-moon
Disallow: /secret-list-of-contacts.php
Allow everything but specific patterns of URLs
Your website might have some patterns of URLs that you want to disallow and can be grouped into a particular sub-directory. For example:
User-agent: *
Allow: /
# Disallowed URL Patterns
Disallow: /*search=
Disallow: /*_test.php$
Disallow: /*?page=*
What should not be included in the robots.txt file?
The following command is included in a website that has a robots.txt file:
User-agent: *
Disallow: /
This means that it is instructing all bots to ignore the entire domain and none of the webpages or files should be listed in search results. The example above shows the importance of implementing a robots.txt file in the right way and ensuring that it is not restricting the chances of being indexed by search engines.
Putting it all together
While you may be willing to use a combination of these methods to block different areas of your website, there are key things to remember, such as:
- If you forbid a sub-directory then ANY file, sub-directory or webpage within that URL pattern will be prohibited.
- The star symbol (*) substitutes for any character or number of characters.
- The dollar symbol ($) signifies the end of the URL, without using this for blocking file extensions, you may block many URLs by accident.
- The URLs are case sensitive, which means you may have to put in both caps and non-caps options to grab them all.
- It can take search engines many days or even a few weeks to notice a forbidden URL and remove it from their index.
- The “User-agent” setting permits you to block certain crawler bots or treat them differently. If needed, a which substitute the catch-all star symbol (*)
Google has put together an overview of what’s blocked and what’s not block on their in-depth robots.txt file page. Have a look:
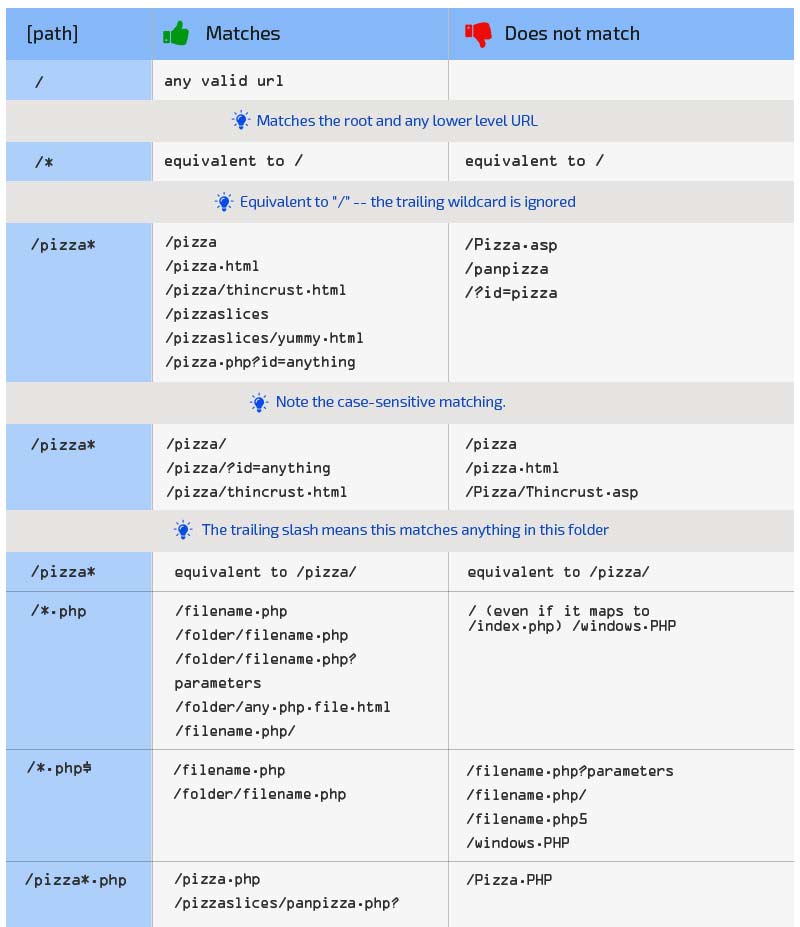
WordPress Robots.txt for great SEO
Google has come a long way, and it now fetches everything and renders webpages fully. But when you deny access to CSS or JavaScript files, Google does not appreciate it and isn’t happy. Blocking access to your wp-includes directory and your plugins directory via robots.txt is no longer valid. Many themes also use asynchronous JavaScript requests – so-called AJAX – to add content to web pages. WordPress used to block Google from this by default, but that was fixed in WordPress 4.4.
Robots.txt denies links for their value
One of the essential things to remember is that if you are using your site’s robots.txt to block a URL, search engines will not crawl it. Eventually, it will not allow distributing the link value directing to the blocked URLs. Thus, if your website has a number of links pointing at it and you’d rather not have appear in search results, don’t block it via robots.txt, instead use a robots meta tag with a value of “noindex, follow“. This means it will allow search engines to distribute the link properly for the targeted pages of your website.
WordPress robots.txt example
The most important question is about what should be included in your WordPress robots.txt file. Do not block /dir/plugins/ directory, as plugins might output JavaScript or CSS that Google needs to render the page. Also, don’t block your /wp-includes/ directory, as the default JavaScript that comes with WordPress, which many themes use, lives there.

Also, do not block your /wp-admin/ folder because if you block it but link to it somewhere by chance, people will still be able to do a simple [inurl:wp-admin] query in Google and find the site. WordPress now has a robots meta x-http header on the admin pages that will prevent search engines from displaying them in search results, which is a much cleaner solution.
Testing the Usefulness of Robots.txt
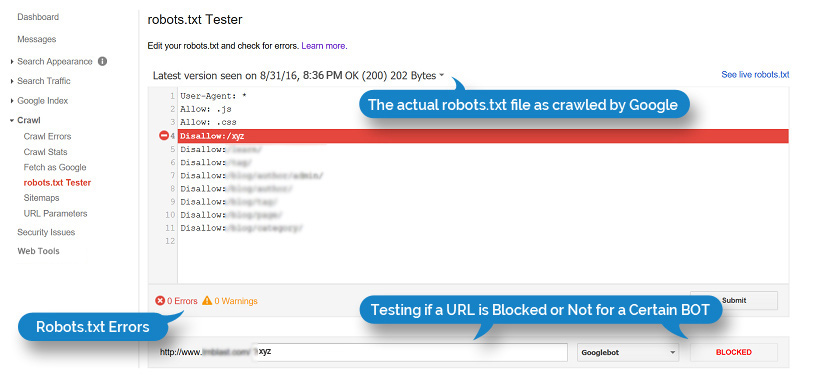
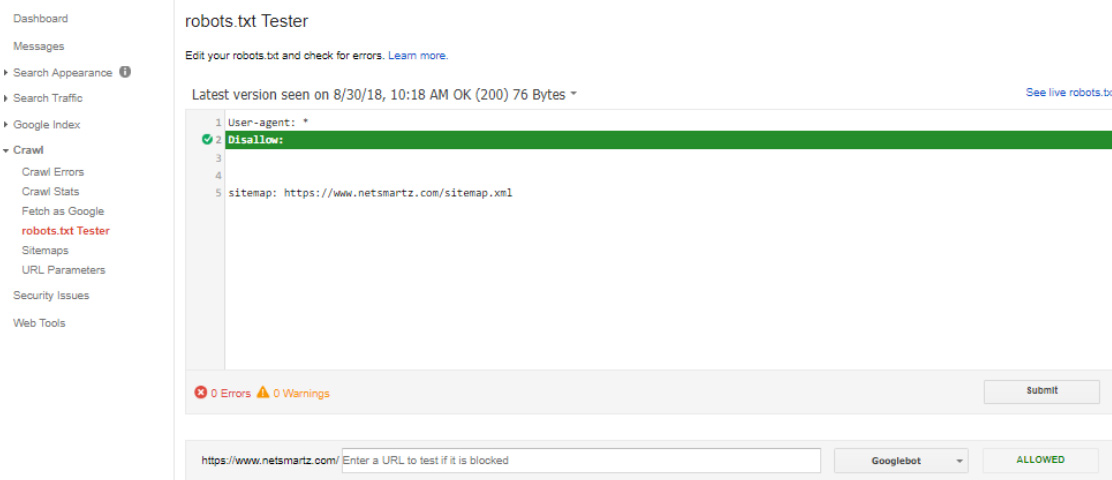
To check the utility and results of your robots.txt file, your website must be verified and registered with the Google Webmaster Tools. Google has already created the testing tool for robots.txt. You select the website from the registered list in Google Search Console and Google will return with notes and highlighted errors. Look at the below examples.
Robots file with errors:
Robots file without errors:
The Benefits of Robots.txt
Robots.txt is the method that helps webmasters instruct search engines to visit specific pages or directories on a website. They have the freedom to allow specific bots to crawl selected pages of a site. Robots.txt includes a sitemap URL which instructs search engines to find the location of your sitemap easily.
It is useful if you do not wish search engines to:
- Index certain areas of the website or a whole website
- Index specific files on a website (images, videos, PDFs)
- Prevent duplicate content pages from appearing in SERPs
- Index entire sections of a private website (for instance, your staging site or an employee site)
If you have a robots.txt file, then it will be easy for search engines to find the XML sitemap for the latest content without crawling all the pages on your website and running into them days later. If your site is not performing well and the webpages are not indexed correctly, your position within the search engine results is compromised. To evade such issues and make sure none of the webpages are blocked, seek help from digital marketing experts.
Summary
Kickstart Your Project With Us!
Blog
Popular Posts





CONTACT US
Let's Build Your Agile Team.
Experience Netsmartz for 40 hours - No Cost, No Obligation.
Connect With Us Today!
Please fill out the form or send us an email to